
(What follows will be a somewhat technical discussion on how bacteria defend themselves against viral infections and how CRISPR gene-editing can be used to modify the genomes of stem cells and living organisms. This article will be a technical discussion on how CRISPR gene-editing actually works and it is dedicated to a series of lectures given by a YouTuber named Ben Garside. In another less technical article, I will discuss the extraordinary applications of CRISPR gene-editing and variations of the CRISPR method.)
CRISPR gene editing is a technique which bio mimics how a bacterium responds to a viral infection. The CRISPR-CAS9 system was first discovered by Jennifer Doudna and Emmanuelle Charpentier and is found specifically in a type of bacteria known as Streptococcus Pyogenes. Both of them won the Nobel Prize for their discovery. The CRISPR-CAS9 system is a bacterium’s immune system against viral infections. It wasn’t until the years 2011 through 2012 that researchers realized that this system could be used to modify genomes in living organisms. The implications of this new power we have obtained are profound and revolutionary, but I'll save the discussion about them for a separate article.
![ Figure 1 Source\(^{[1]}\)](https://images.squarespace-cdn.com/content/v1/58757ed7f5e231cc32494a1b/1497325305298-O3IE8YGKX5OSRAJ6DIFB/image-asset.png)
Figure 1
Source\(^{[1]}\)
Viruses which particularly target bacteria are known as bacteriophages (illustrated in Figure 1). When a phage attacks a bacterium, it “lands on” the surface of the bacterium and then starts to insert copies of its DNA into the bacterium. After a bacterium is attacked by a virus, if it survives (which it rarely does), it will store copies of segments of the viral DNA in its genome. When the bacterium is attacked by a virus again, it sends two small strands of RNA (one of which matches sections of the genome of the virus's DNA) to a protein called CAS9. CAS9, in particular, is an enzyme which exists in Streptococcus Pyogenes and acts as an immune system against viruses; but more generally, other bacteria and archaea have analogous enzymes (generally called CAS enzymes) which also function as immune systems against viral infections. The RNA strands connect to a small section of the CAS9. After this, the CAS9 searches through all the DNA in the bacterium until it finds the strand of DNA corresponding to that of the virus. The CAS9 then comes into physical contact with the DNA which the virus inserted, untangles the DNA, then a matching RNA strand attaches to the DNA, and lastly the CAS9 acts as “scissors” and is able to physically cut off and remove a section of the viral DNA—this effectively deactivates the virus.
By doing many experiments, researchers realized that it is possible to replicate this natural process in the center of any cell in any species. Every cell in the human body contains a copy of the human genome—a collection of billions of base pairs and roughly 20,000 genes. Researchers realized that CAS9 is “programmable”: you can simply attach any mRNA sequence to it, insert the CAS9 into any cell, and it will hunt down and look for that particular DNA sequence (that is complementary to the mRNA) inside of the cell. When it finds it, the CAS9 will attach to it, cut it off, and deactivate the DNA sequence.
Figure 2
After a phage attacks the bacterium and inserts copies of its DNA into it, the bacterium will cut off pieces of the viral DNA and store it in its own genome. It stores these DNA segments in a portion of its genome known as the CRISPR locus. This stored DNA segment is used the next time a phage attacks it. What does the structure of the CRISPR locus look like? In Figure 2, the sequences of nucleotides labeled "spacers" are known as CRISPR repeats; all of the CIRSPR repeats are identical sequences of nucleotides. The pieces of viral DNA segments get stored in the spaces in between the CRISPR repeats (labeled as “spacers” in Figure 2). As phages continue to attack the bacterium cell inserting more and more copies of fragments of its genome, the bacterium will continue to cut off more pieces of the viral DNA strands. All of these pieces get stored in the spaces in between the CRISPR repeats. Each new, additional, cut off piece of viral DNA gets stored at the 5’-end of the coding strand as illustrated in Figure 2.
One of the strands of the CRISPR locus (called the coding strand) is “read” by DNA polymerases which then create mRNAs that are identical to the coding strand. These are called CRISPR RNAs (or crRNAs for short). A crRNA binds to another kind of RNA known as transactivating CRISPR RNA (or tracrRNA for short); this is possible because a CRISPR repeat portion of the crRNA is complimentary to a portion of the tracrRNA. The crRNA-tracrRNA system (which is called the guide RNA or gRNA for short) then binds to a CAS enzyme. When the next virus tries to attack the bacterium, the CAS-gRNA complex finds the viral DNA and cuts it up making the viral DNA functionally useless.

Figure 3
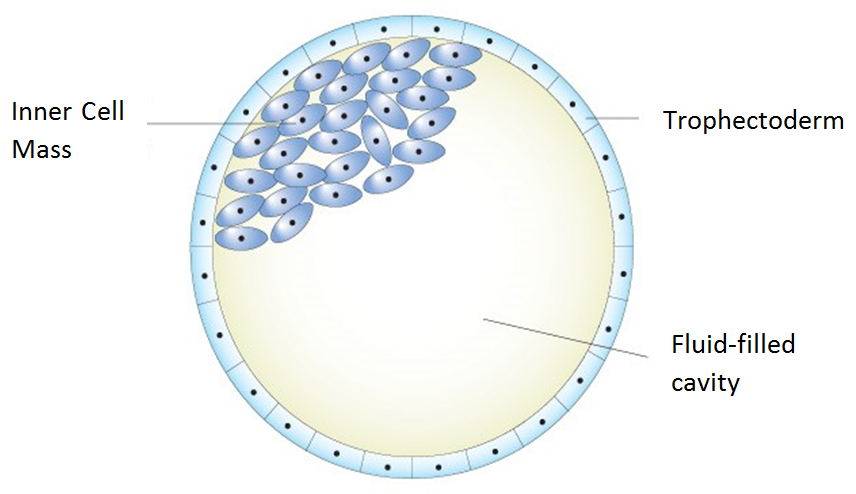
We shall now discuss how the CRISPR-CAS9 system can be used to produce knockout mice—that is, mice with a modified genome. A blastocyst is what a mouse is in its earliest stages of development. A blastocyst (illustrated in Figure 3) consists of a collection of stem cells (which are, collectively, called the inner cell mass) in a fluid-filled cavity known as the blastocoel, and a collection of cells (called the trophoblast) surrounding both the inner cell mass and the blastocoel. The stem cells can be taken out of the blastocyst and cultured in a petri dish. To create a knockout mouse, the first thing we’ll need to do is take out the stem cells from the blastocyst, then remove a gene from each stem cell using CRISPR-CAS9 gene editing, then put the stem cells back into the blastocyst. The blastocyst will eventually turn into a mouse with some of its cells no longer having this particular gene. These particular cells which don’t have the gene are then used to create a fertilized egg which will turn into a mouse. All of this mouse’s offspring will not have the gene.
After stem cells have been transported from the blastocyst to the petri dish, scientists can incubate all of these stem cells with CAS9 enzymes. After doing this, scientists are actually able to design and make mRNA strands with any sequence of nucleotides they want. Let’s say that we want to remove Gene A from each stem cell. In Figure 4, you can see that the portion of the stem cell’s genome to “the left” of Gene A is highlighted in blue and the portion of the stem cell’s genome to “the right” of Gene A is highlighted in red. If scientists want to remove Gene A, what they’ll do is design two mRNA strands (one of which is complimentary to the “blue portion” of the genome and the other complimentary to the “red portion”) and then, after that, they’ll incubate each stem cell with the two mRNA strands. Each mRNA strand will have a CRISPR repeat. The rest of the mRNA strands will consist of sequences of nucleotides which are complimentary to the blue and red portions of the genome. When these mRNA strands are put into the stem cell, the CRISPR repeats will bind to tracrRNAs. After this, the mRNA-tracrRNA systems will attach to CAS9 enzymes. After that happens—in each stem cell—the CAS9s will hunt for the portions of the genome which contain the red and blue portions. It’ll then attach to those portions and cut them off. The end result of what the genome looks like is illustrated in Figure 4.

{kind=link}
Figure 4 (click to enlarge)
In this paragraph, we’ll have a brief side discussion of different ways a cell can repair a double-strand break in its genome. For the purposes of CRISPR-CAS9 gene editing, this is something we do not want the cell to do. When a double-strand break occurs in a portion of a cell’s genome, there are two different possible things the cell will do to try to repair the double-strand break. Most of the time the cell will “trim back” the overhang on each side of the DNA and then put the two strands back together. This is called non-homologous end joining (NHEJ). But sometimes the cell will get information from either a homologous DNA strand or a sister chromatid and use this information to repair the double-strand break and restore the gene. This process is known as homologous recombination. When a cell is about to divide, it will create an identical copy of every one of its chromosomes; these identical copies are called sister chromatids. All of the missing base pairs in a cell's chromosome due to the double-strand brake can be replaced with 100% accuracy. Most organisms have a pair of every one of their chromosomes. These are called homologous chromosomes. Homologous chromosomes, unlike sister chromatids, are not completely identical but they are almost identical. If a cell uses a homologous chromosome to repair a double-strand brake, it’ll replace the missing nucleotides with almost the same nucleotides. The repaired gene would be similar enough to code for more or less the same things. We’ll assume that the nucleotides in the homologous chromosome are identical to the missing nucleotides in the other homologous chromosome. The way that homologous recombination works is that, in the region where the double-strand break is, the 5’-ends of each strand get trimmed back as shown in Figure 4 and 5. What happens next is the chromosome (the one with the double-strand break) will come into physical contact with its homologous chromosome which we'll call Chromosome B (this process is called strand invasion). A portion of the top strand of Chromosome B will bind to the portion of Chromosome A that is the 3’-overhang. DNA polymerase are able to extend the 3’-overhang and they create a sequence of nucleotides which is complimentary to the top strand of Chromosome B. Although I am describing what is happening to the "left strand" of Chromosome A, of course, the right strand of Chromosome A goes through a completely analogous series of operations. As illustrated in Figure 5, since we are assuming that Chromosome B is identical to Chromosome A, this must mean that the created nucleotides are identical to the nucleotides Chromosome A has before the double-strand break even occured. This process of DNA repair effectively restores the “lost” nucleotides. We will assume that these nucleotides are 100% restored (with perfect accuracy) to what they were prior to the double-strand break.
To create a knockout mouse, scientists (in addition to inserting CAS9 enzymes and CRISPR RNAs) will insert DNA strands (into each stem cell) whose base pairs are identical to that of Chromosome A’s except without having Gene A. They’ll only have the entire blue and pink portions of Chromosome A bounded together. Chromosome A will then strand invade this inserted DNA strand and perform homologous recombination. Chromosome A will restore all of its missing base pair associated with the blue and pink portions; but it will do this without restoring Gene A. This process does not have a 100% success rate. Some of the stem cells (which we successfully knocked Gene A out of) will differentiate into cells with no Gene A in them, whereas other stem cells will retain Gene A and differentiate into cells which still have Gene A. Some of the stem cells (without Gene A) will differentiate into germ cells. These cells in particular are the ones where interested in because these cells can produce egg cells and sperm cells with no copy of Gene A. We can then infuse the sperm cell into an egg cell to produce a blastocyst which will have no copy of Gene A. The blastocyst will eventually turn into a mouse without Gene A.
To create a knockout mouse, scientists (in addition to inserting CAS9 enzymes and CRISPR RNAs) will insert DNA strands (into each stem cell) whose base pairs are identical to that of Chromosome A’s except without having Gene A. They’ll only have the entire blue and pink portions of Chromosome A bounded together. Chromosome A will then strand invade this inserted DNA strand and perform homologous recombination. Chromosome A will restore all of its missing base pair associated with the blue and pink portions; but it will do this without restoring Gene A. This process does not have a 100% success rate. Some of the stem cells (which we successfully knocked Gene A out of) will differentiate into cells with no Gene A in them, whereas other stem cells will retain Gene A and differentiate into cells which still have Gene A. Some of the stem cells (without Gene A) will differentiate into germ cells. These cells in particular are the ones where interested in because these cells can produce egg cells and sperm cells with no copy of Gene A. We can then infuse the sperm cell into an egg cell to produce a blastocyst which will have no copy of Gene A. The blastocyst will eventually turn into a mouse without Gene A.
This article is licensed under a CC BY-NC-SA 4.0 license.
References
1. http://www.nature.com/nrmicro/journal/v6/n3/abs/nrmicro1793.html
2. http://fertilitysolutions.com.au/wp-content/uploads/2014/12/Day-5-6-Blastocyst-Schematic.png
3. https://www.youtube.com/channel/UCu5cg_Jd9XSJL_CHUskgkGw